ConTeXt MkIV 中文标点间距压缩问题的解决方案
有关在 ConTeXt MkIV 中解决中文标点符号微排版的话题,在背景一文中已做过介绍。为这个问题已经潜水很久,现在才开始准备浮出水面。这篇文章主要总结一下这段时间所做过的一些有关中文标点间距压缩方面的尝试,这样即便我受到一些外因的限制无法完成此事,也可对其他有志于此者有所帮助。
中文字体
我在不仅仅是为了中文中有过较为详细的介绍,可以考虑以下三种方式实现 ConTeXt 对中文字体的支持:
- 自己写 typescript 文件
- 使用 Wolfgang 所写的 simplefonts 模块
- 在 http://bbs.ctex.org/viewthread.php?tid=54677 上可以找到我最近重新改写的 zhfonts 模块
在试验阶段,我打算先将中文标点处理部分的代码独立出来,等它成熟后再挂到 zhfonts 模块中。
框架
假设所使用的 ConTeXt 环境为 ConTeXt Minimals,并且其安装目录为 /opt/context(下 文用 CTX 作为这一目录的代称),那么请自行建立 /opt/context/tex/texmf-local/tex/context/third/zhcnpuncs 目录(下文采用 ZHCNPUNCS 作为这一目录的代称),在该目录中创建一份 lua 程序文件 zhcnpuncs.lua,内容如下:
zhcnpuncs = zhcnpuncs or {}
function zhcnpuncs.opt ()
end
然后在相同目录中创建 t-zhcnpuncs.tex 文件,内容如下:
\writestatus{loading}{Context User Module / zhpuncs}
\startluacode
dofile (kpse.find_file ('zhcnpuncs', 'lua'))
\stopluacode
\def\optzhpuncs{\ctxlua{zhcnpuncs.opt}}
\endinput
然后,我们在 ConTeXt Minimals 的工作环境中刷新一下目录树:
$ source CTX/tex/setuptex $ luatools --generate
在 ConTeXt 文稿中,加载 zhcnpuncs 宏包,通过控制序列 \optzhcnpuncs 即可调用 zhcnpuncs.lua 中定义的函数 zhcnpuncs.opt:
% 假设使用 zhfonts 来加载中文字体 \usemodule[zhcnfonts] % 加载 zhcnpuncs 模块 \usemodule[zhcnpuncs] % 调用 zhcnpuncs.opt 函数 \optzhcnpuncs % 启用中文字体 \usezhcnfonts[rm,12pt] \starttext 测试,测试。测试“测试”…… \stoptext
这样,我们只需要在 zhcnpuncs.opt 函数中去处理中文标点符号即可。
想更多了解一些 ConTeXt 模块的知识可以阅读文档 [1] 和文档 [2]:
[1] 基本的 Module 知识:http://bbs.ctex.org/viewthread.php?tid=50636
[2] ConTeXt 内幕:http://wiki.contextgarden.net/Inside_ConTeXt
时机
有了框架之后,比较关键的问题就是怎么才能查知 ConTeXt 文稿中所使用的中文标点种类、数量及其在文稿中的位置。
LuaTeX 提供了一些回调函数,允许用户在 LuaTeX 对 TeX 文稿的处理过程的不同阶段插入自己实现的一些功能。用户只需要将自己实现的函数挂接到特定的回调函数,那么 LuaTeX 会在特定的时机去调用用户所实现的函数。
利用 LuaTeX 的回调函数机制,用户在 LuaTeX 的数据处理、断行之前和断行之后等阶段皆可以获取到中文标点种类、数量及其在文稿中的位置信息。
在数据处理阶段,由于标点符号的信息量不足,用户仅能够对标点符号的排版实现比较生硬的控制,而无法根据标点符号所对应字体的轮廓信息适应性地调整 其位置及前后间距。如果选择这个阶段对中文标点符号进行处理,需要依赖具体的字体。也就是说对于 Adobe 宋体所做的标点处理,对于 SimSun 宋体就不再适合了。
在断行之后的阶段,由于分行已经结束,这时对标点再进行排版会破坏 LuaTeX 已经确定的版面,所以也不可取。
唯一可行的就是在断行之前的阶段,那时 LuaTeX 已经将 TeX 文稿的所有信息都处理成了结点 (node) 的形式,这些结点的数据结构中包藏了足够的信息,例如可以查知标点符号结点当前所使用的字体以及标点字符轮廓的最小包围盒信息等。根据这些信息,可以较为 灵活地实现标点排版控制,可以做到不依赖具体的字体。
LuaTeX 对断行之前的回调函数 pre_linebreak_filter 的格式是这样定义的:
function(<node> head, <string> groupcode)
return true | false | <node> newhead
end
函数的参数 head 表示 LuaTeX 向 pre_linebreak_filter 所传入的结点链表 (node list) 的首结点; groupcode 参数是一个字串,表示结点链表的类型,当它取值为空时,表示结点链表类型为“main vertical list”,通常我们只需要处理这种类型的结点链表即可,因为它表示的是 TeX 文稿的主要部分。除了main vertical list 类型之外,许多其它的类型,有时候选择性的跳过某些类型的结点链表,可以提高程序运行效率。
下面介绍一下回调函数 pre_linebreak_filter 的用法。首先可在 ZHCNPUNCS/zhcnpuncs.lua 文件中定义一个函数,譬如 my_pre_linebreak_filter:
local function my_pre_linebreak_filter (head, groupcode)
return true
end
然后再 zhcnpuncs.opt 函数中进行回调函数注册:
function zhcnpuncs.opt ()
callback.register ('pre_linebreak_filter', my_prelinebreak_filter)
end
这样,在 LuaTeX 开始对 TeX 文稿进行断行前总是会调用我们自定义的 my_pre_linebreak_filter 函数。
值得注意的是,如果他人在此之前已经对这一回调函数进行了注册,它会被这样简单而又粗暴的回调函数注册方式破坏掉。可以采用下面的回调函数注册方式来规避这个问题:
-- 查一下他人的 pre_linebreak_filter 回调函数并保存
local old_pre_linebreak_filter = callback.find ('pre_linebreak_filter')
local function my_pre_linebreak_filter (head, groupcode)
-- 尊重他人,先执行他的 pre_linebreak_filter 回调函数
if old_pre_linebreak_filter then
old_pre_linebreak_filter (head, groupcode)
end
-- 下面是我们的功能实现
return true
end
function zhcnpuncs.opt ()
callback.register ('pre_linebreak_filter', my_pre_linebreak_filter)
end
结点
上文介绍了 pre_linebreak_filter 回调函数所接受的参数是结点链表,那么在其实现中就可以按照下面这种方式其进行遍历:
local old_pre_linebreak_filter = callback.find ('pre_linebreak_filter')
local function my_pre_linebreak_filter (head, groupcode)
if old_pre_linebreak_filter then
old_pre_linebreak_filter (head, groupcode)
end
-- 跳过非 main vertical list 类型的结点链表
if groupcode ~= '' then return true end
for n in node.traverse (head) do
texio.write_nl (node.type (n.id))
end
return true
end
上述代码所实现的功能仅仅是在终端中打印出类型为“main vertical list”的结点链表中每个结点的类型。
LuaTeX 提供了许多种结点类型,它们对应着 TeX 中的一些“对象”。要想真正了解这些结点的含义,对 TeX 的认识要比较全面才可以。现在基本上可以确定,对于解决中文标点间距压缩问题,只需要了解 glyph 和 kern 这两种类型的结点的含义及如何构建即可。
首先来看 glyph 结点,在 luatex 的参考手册中对它的数据结构是这样定义的:
field type explanation subtype number bitfield attr <node> char number font number lang number left number right number uchyph boolean components <node> pointer to ligature components xoffset number yoffset number
“field”列表示 glyph 结点所包含的成员,“type”列表示成员类型,其中对于中文标点间距压缩问题较为重要的成员主要为 char、font、xoffset 和 yoffset。glyph 结点的 char 和 font 成员,均为数字类型,分别用于代指该 glyph 结点对应的字符编号以及所用的字体编号;xoffset 与 yoffset 分别表示 glyph 结点水平与竖直方向上的偏移距离(可以取负值)。
下面,我们对上述的 的 my_pre_linebreak_filter 函数作以下修改:
local glyph_flag = node.id ('glyph')
local fontdata = fonts.ids
local function my_pre_linebreak_filter (head, groupcode)
if old_pre_linebreak_filter then
old_pre_linebreak_filter (head, groupcode)
end
if groupcode ~= '' then return true end
math.randomseed (os.time ());
for n in node.traverse (head) do
if n.id == glyph_flag then
local r = math.random ()
n.yoffset = r * fontdata[n.font].size
end
end
return true
end
上述代码中,font.ids 是 ConTeXt MkIV 为保存 luatex 所加载字体的相关信息而构建的一个表,我们可以访问这个表来查询当前 glyph 结点对应字体的一些信息,譬如当前字体尺寸——fontdata[n.font].size。这个修改后的 my_pre_linebreak_filter 函数可以实现让 ConTeXt 文稿中的文字“跳舞”。例如对于下面的文稿:
\usemodule[zhfonts] \usemodule[zhcnpuncs] \optzhcnpuncs \usezhfonts[rm, 12pt] \starttext \starttyping 来吧,我亲爱的人,今夜我们在一起跳舞。 来吧,孤独的野花,一切都会消失。 你听窗外的夜莺,路上欢笑的人群…… \stoptyping \stoptext
排版输出效果如下图所示:

下面再来看 kern 结点,它对应 TeX 控制序列 \kern,用于向文稿中插入一个可以控制宽度的空格。kern 的宽度可以为负值,这样可以起到缩短其相邻字符间距的功能。在 LuaTeX 参考手册中,对 kern 结点的数据结构是这样定义的:
field type explanation subtype number 0 = from font, 1 = from \kern or \/, 2 = from \accent attr <node> kern number
kern 结点比较重要的参数就是 "kern",它是一个数值变量,用于定义 kern 的宽度。
下面我们对那个让文字跳舞的 my_pre_linebreak_filter 函数略做作一下修改:
local function my_pre_linebreak_filter (head, groupcode)
if old_pre_linebreak_filter then
old_pre_linebreak_filter (head, groupcode)
end
if groupcode ~= '' then return true end
math.randomseed (os.time ());
for n in node.traverse (head) do
if n.id == glyph_flag then
local r = math.random () * fontdata[n.font].size
n.yoffset = r
node.insert_after (head, n, nodes.kern (r))
end
end
return true
end
所做的改动就是使用 node.insert_after 函数向当前结点 n 之后插入一个采用 nodes.kern 函数(它是 ConTeXt MkIV 定义的)生成的 kern 结点。插入 kern 结点后的排版输出效果为:

字符边界盒与字符位置的调整
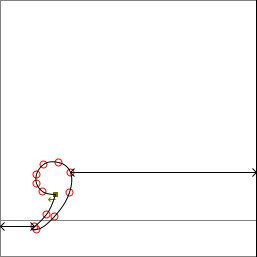
LuaTeX 可以在加载字体时,可以比较精确的计算出包含字符的字形轮廓的近似最小包围盒——边界盒。例如对于中文逗号标点,如下图所示,外围的矩形域表示该字符在设计之时被赋予的空间,内部的矩形即为其边界盒。

对于中文字符而言,外围的的矩形区域是在字体设计时就确定的,可以称之为“字符排版空间”,排版软件只需要针对字符排版空间在版面上合理的安排与放 置字符即可完成排版的主要任务(当然,实际上并不是我说的这么简单)。正因为如此,所以排版软件是很难解决因中文标点符号设计的不合理而导致的排版问题。 譬如上图中的中文逗号标点,它在排版时所占据的版面宽度就是它的外围矩形的宽度一样大。
在中文排版中,如果单个中文标点,勉强是可以接受的。当多个中文标点相邻时,它们所占据的版面宽度累加起来,在视觉上就难以容忍了,例如下图所示的中文逗号与中文左引号相邻时,这两个标点符号之间的空白区域要大于一个汉字的宽度,看起来非常丑陋。

做为对比,西文字体在设计上,如下图所示,字符的宽度通常仅比其外形轮廓宽度略微大一些而已(等款字体除外),并且西文标点符号的间距可以通过空格来调整。
 空格的宽度
空格的宽度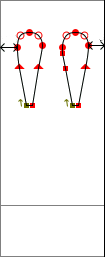
我们在阅读很多西文的书籍时,稍微细心就可以看出页面右侧靠近边界的文本从竖直方向上看去, 非常整齐,而中文书籍,特别是那些使用 Word 这个字处理器排版的中文书,页面右侧靠近边界的文本从竖直方向看去,诘屈聱牙的很,即便那个写过《Word 排版艺术》的人所排版的书也不例外,见下图。这个问题也是拜中文标点符号间距较宽所赐,不过一些专业的排版软件是可以对中文标点符号进行“压缩”与“边界 对齐”处理(其实这也是本篇文档致力要解决的主要问题)。

对中文标点进行间距压缩,对于 TeX 而言,一直都不是很容易的事情,现有的解决方案通常是根据具体的中文字体来确定间距的压缩长度。当 LuaTeX 可以计算出字符轮廓的边界盒时,这个问题便很好解决了,并且可以做到与具体中文字体无关。嗯,再一次感谢 yulewang 当初对这一解决方案的宣传!
前文中介绍过,ConTeXt 将 LuaTeX 所加载字体的相关信息存储在 font.ids 表中,其中自然是包含了各个字符的边界盒信息。继续对前文中已经改了好几遍的 my_pre_linebreak_filter 函数进行修改,使之可以在终端中打印出文稿中所有 glyph 结点的边界盒信息,具体代码如下:
local old_pre_linebreak_filter = callback.find ('pre_linebreak_filter')
local myprint = texio.write_nl
local glyph_flag = node.id ('glyph')
local fontdata = fonts.ids
local function my_pre_linebreak_filter (head, groupcode)
if old_pre_linebreak_filter then
old_pre_linebreak_filter (head, groupcode)
end
if groupcode ~= '' then return true end
for n in node.traverse (head) do
if n.id == glyph_flag then
desc = fontdata[n.font].descriptions[n.char]
myprint ('BoundingBox:')
for k in pairs (desc.boundingbox) do
myprint (desc.boundingbox[k])
end
myprint ('width = ' .. desc.width)
end
end
return true
end
上述代码中,fontdata[n.font].descriptions[n.char] 表中包含了 glyph 结点 n 的边界盒信息及其宽度信息。这段代码可以打印出每个 glyph 结点对应的边界盒及 glyph 宽度信息,例如对于 SimSun 宋体的中文逗号和左引号,它们的边界盒与宽度信息分别如下:
# 中文逗号 BoundingBox: 28 -10 73 60 width = 256 # 中文左引号 BoundingBox: 118 117 223 197 width = 256
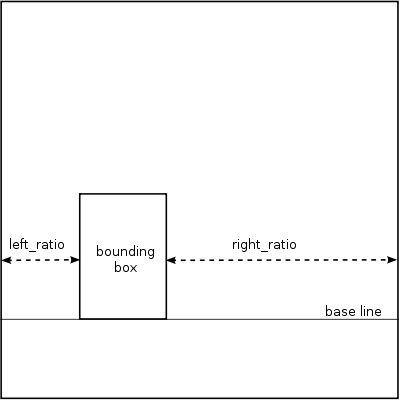
上述边界盒与宽度信息只能用于计算中文标点符号在水平方向上的间距压缩,计算模型如下图所示,只需要计算出水平方向上的位置调整比例,然后在 glyph 结点前后插入由位置调整比例及当前字体尺寸确定的 kern 结点即可。
水平方向的标点压缩问题有了解决方案之后,再来看中文字符在竖直方向上的位置调整问题。解决中文标点符号在竖直方向上的定位对于在 ConTeXt MkIV 使用台湾文鼎公司免费发布的那套字体来排版简体中文具有重要意义。文鼎的字体,许多标点符号在设计时,被定位到字符空间的正中位置,比如中文逗号、句号 等,而简体中文的排版要求是这些符号应当居于字符排版空间的左下侧。
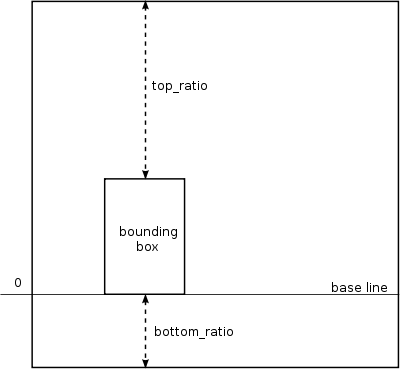
对于中文标点符号在竖直方向上的位置调整,单纯基于边界盒信息是无法做到的,虽然中文字符的排版空间的高度确是有可能得到,在 fontdata[n.font].descriptions[n.char] 表中有一个 vwidth 的成员,它记录的是那些可以用于竖排的字体的“高度”,但是字符边界盒在竖直方向上的零点是位于字符基线的位置,而我们无法得知基线距离字符排版空间底线的距离,因此就无法对字符边界盒在竖直方向上的位置调整提供如下图所示的足够精确的位移信息。或许是有办法,现在的我还很菜,没有能力搞清楚。
不过,可以给出一些用于在竖直方向上调整中文标点符号的 lua 接口,并定义一组 ConTeXt 控制序列,以便用户可以根据自己的经验去手动调整某些标点符号的位置。
也就是说,对于水平方向上的中文标点字符处理,我们可以提供调整机制及默认的策略,而对于竖直方向的中文标点字符处理,只能提供调整机制。
总结
将上述各个环节综合起来,就可以得到中文标点符号的间距压缩问题的较好的解决方案,剩下的工作就是写程序,而另外一个有关中文标点微排版的重要问题是“边界对齐”——让标点挂在文字块的边线上——对于我来说,还需要再了解一些必需的知识,意味着还要潜水……水还真是深啊……
2009年12月05日 05:09
太强了,我虽然不懂,但还是觉得博主非常强大。博主加油!